
序文
前回、コミケのカタログからサークル画像を切り出しました。
サークルリストから文字認識をする予定でしたが、枠線を消さないと、やっぱり誤認識が多い感じでしたので、もうちょっと手を加える予定です。
なので、今回は先にクラスタリングをしてみようと思います。
目的
コミケのサークル画像をk-meansでクラスターに分ける。
ざっくり1日8000サークル。4日で32000サークル。
ちょっと自信がないので、1日分、初日の8000サークルを対象にやってみようと思います。
※実際は8190サークル画像でした
事前準備
前回を参考に適当なサイズの画像を沢山用意してください。
今回はコミケのサークル画像8190ファイルでやってます。
選手名鑑でもお好きな画像をどうぞ。
次にソフトウェアですが、Daskを入れておきます。
サイズが大きいので実メモリに収まる気がしなかったので入れました。
Out-of-Core処理をするんだろうぐらいの感覚。
実際に必要だったか不明。
OpenCVまでは8GBメモリのノートパソコンで実施してましたが、今回は32GBのデスクトップパソコンで処理させました。
features = np.array([cv2.imread(p,cv2.IMREAD_GRAYSCALE) for p in files])上記のデスクトップパソコンでは上記コードでも動きました。
ノートパソコンではMemoryErrorでした。
で、それはさておきインストール。
pip install dask
pip install dask-ml画像ファイルを開く
前回同様、画像ファイルを読み込むんですが、大きいんでdask.arrayにする。
dask-sampleを見て、こんなもんだろう的なやっつけ。
for file in files:
im = cv2.imread(file)
im_gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
im_gray = im_gray.reshape(PIX)
src.append(da.from_array([im_gray]))
dest = da.concatenate(src, axis=0)気になってmemory_profilerで喰ってるメモリを調べたら1166.3 MiB。
上でも書いたnumpyで入れ込むと1135.8 MiB。
なんだよ、増えてるじゃん。
何か間違った使い方してるんだろうな。
とりあえず動いてるから次。
ここで値を255で割って0-1の間(float)にする方がよいようですが、やってない例もあるっぽいので、とりあえず放置。
メモリ使用量(余談)
ちなみにメモリプロファイラはこんな感じで使う。
from memory_profiler import profile
@profile
def main():
hogehoge
if __name__ == '__main__':
main()次元圧縮
言い忘れましたが、この状態ではこんな感じになってる。
[[140 174 172 … 132 94 59] ← 129000
[128 173 179 … 50 57 71]
[142 144 143 … 61 57 49]
…
[132 194 203 … 61 40 39]
[154 190 191 … 83 53 60]
[160 173 171 … 84 50 42]]
↑
8190
1画像のデータがシリアル化されており、次元は減ってるワケで、この段階で既に疑問はある。
だけど考えない事にする。どうせCNNをそのうちやるから。
話は戻って、このままだと430 x 300で129000も次元があることになる。
ここで主成分分析で圧縮(削減)する事を考える。
寄与率を0.8程度にするのがよいっぽい。
pca = PCA(n_components=n)
pca.fit(dest)
print("PCA: {}".format(sum(pca.explained_variance_ratio_)))nの値を適当に変えて調整する。
PCA(100): 0.615
PCA(150): 0.651
PCA(300): 0.712
PCA(500): 0.758
PCA(750): 0.796
PCA(800): 0.803
PCA(1000): 0.823
上記のような結果だったので、今回、n=800にしてみる。
クラスタリング(とりあえず)
分からないのでクラスタは10にする。勘です。
km = dask_ml.cluster.KMeans(n_clusters=10)
km.fit(comp)
idx = km.labels_.compute()これでindexが取得できる
エルボー法
そもそもこのクラスタ数が正しいのか不明。
そこで残差平方和とクラスタ数のグラフを書いて、クラスタ数を増やしても残差平方和の変化の少なくなるところを探す。
残差平方和は以下で取得する。
y = km.inertia_ちなみに、daskのマニュアルにはintertiaって書いてあって間違ってる。
はじめは何でエラーになるのか分からず。
暫く考えた後、
「ああ、イナーシャか」
って気付く。
で、プロット結果が次。
まずは10刻み。
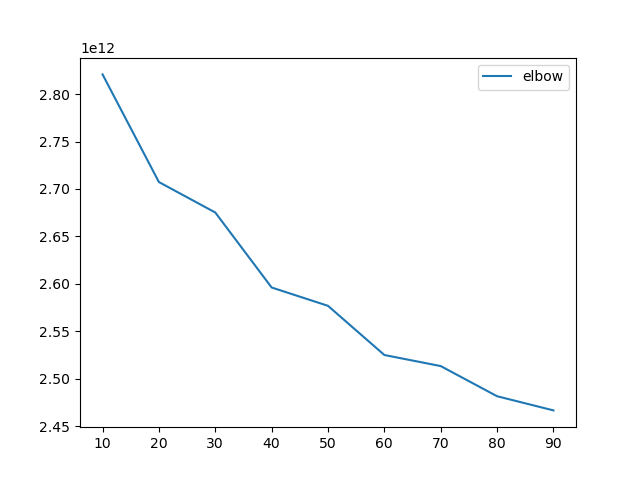
世間のお話通り、エルボー状(L字)にはならない。
あんまり大きなステップでチャートを作成しても分からんです。
10~20の傾きが大きそうなので、5~20でもう一度やってみる。
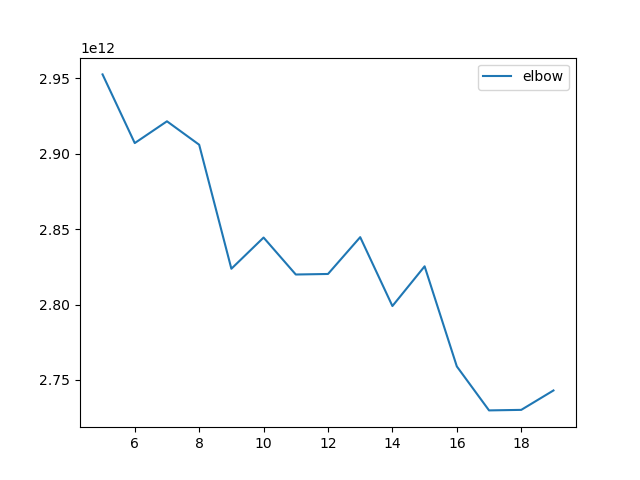
何となく9ぐらいでエエんじゃね?って感じ。
あとは17。
って事で、今回は切りよく10にしました。
つっか、そうやっちゃってたから。
結果

毎度毎度、結果はモザイクです。
とあるインデックスのイメージ結果の一部です。
見た感じでは、全体の平均濃度別に分けられてる感じはある。
なので、文字だけ画像などは纏められてる傾向。
あと、サークル名の欄が「黒ベタ白ヌキ」も纏まってる様に思えます。
重心が似てるんでしょう。
もっともそれ以外に黒ベタが無いって条件だと思いますが。
逆にほぼほぼ黒ベタも纏まってます。
次回
次回こそは、サークルリストの画像を前処理して、OCRに掛けたいと思います。